
Social Justice and Data Science
The responsible conduct of research training you’ve taken has probably brought up all kinds of research practices that were harmful to subjects, such as the Tuskegee syphilis experiment. Researchers have learned that the protection of subjects is tied to both beneficence (research is aimed to provide a better outcome and to improve lives) and justice (the ability to participate in research and benefit from research findings should be extended as broadly as possible). This doesn’t always happen, and little by little we have learned as a community of scientists that we really should:
- Include both male and female subjects (human and animal)
- Consider cultural differences in subject recruitment and participation
- Respect protected groups (like children and prisoners)
- Provide translations of consent and other documents
- Recruit diverse subjects (not just WEIRD subjects – White, Educated, from Industrialized, Rich, Developed countries)
- Consider language choices in writing (“person with autism” or “autistic person”, “disability” or “difference”, etc.)
- Recruit diverse researcher talent at all levels
- Consider correlates (are we really measuring HBP as being different by race, or different by environmental exposure to being a target of racism?)
In the interest of disclosing a recent “teachable moment” in social justice for the data scientist, I share a set of predictors I was given as a dataset for an assignment in grad school (NOT 40+ years ago, I might add):
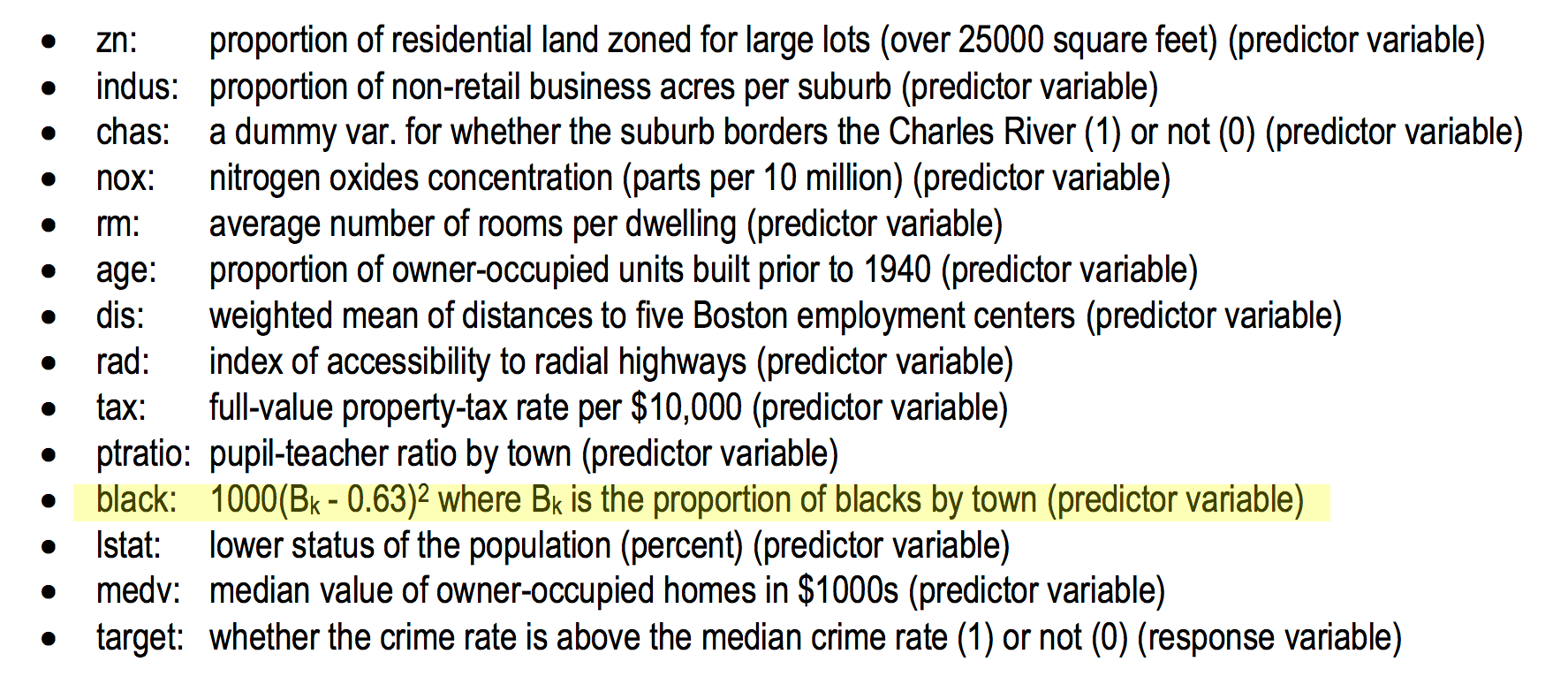
Why did this dataset bother me?
While racial makeup of a neighborhood may correlate to crime rates, I think it’s quite problematic to have a variable that is described as “proportion of blacks by town”, for various reasons:
(1) To say “blacks” instead of “Black people” or “African Americans” is dehumanizing and dated.
(2) To highlight one race is stigmatizing and shows bias in the predictor variables. Why not have the proportion of all races?
(3) Not including strong correlates to race in the US (for example, median income, etc.) means that race alone may have carry a lot of explanatory baggage.
This dataset does have a variable that appears to be related to SES (socio-economic status), which is a good start. At the same time, we know that race correlates to health, wealth, education, and employment differences, not just being “lower status” (itself a problematic turn of phrase that is not explained in the data dictionary). As a data scientist, I question the appropriateness of this set of predictors. We’re able to get nitrogen oxide concentration and rooms per dwelling, but we can’t get median income, unemployment, or data on additional races? I find this unlikely, and the dataset poorly constructed at best, and disingenuous and biased at worst.
Why does this matter to you, as a researcher or data professional? Because science suffers when we don’t ask hard questions about our data and why we collected the data we did. Race is a factor in many things we study, such as osteoporosis and sickle-cell disase. Sex is a factor in many things we study, such as schizophrenia and colorblindness. We shouldn’t shy away from being aware of the actual predictive value of sex, race, country of origin, etc., where appropriate. But we should at the same time be aware that cultural considerations, such as systemic racism and sexism, might affect our questions and our apparent answers.