
Git 101
Version Control 101: Intro to Git
Why does version control matter?
Version control exists in order to give you access to any version of a text file (usually code or configuration files) at any time, with helpful messages that tell you why things changed and by whom. Often, a scientist’s first form of version control is something like this:
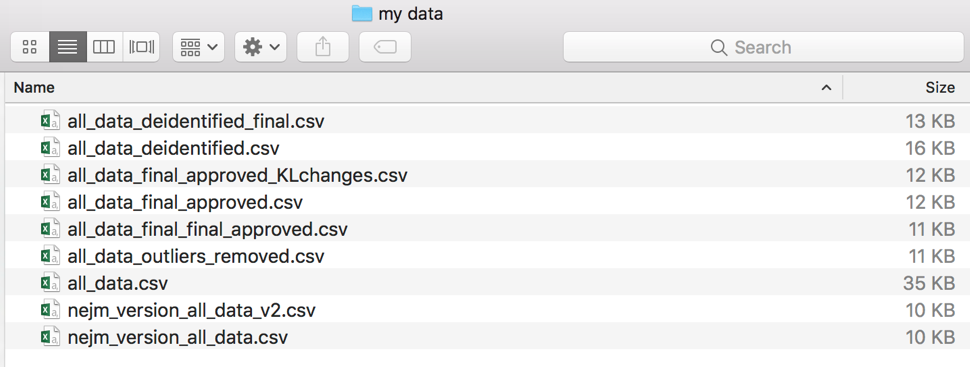
The Bad Old Days
If you have a file system that looks like this, with clues embedded in file names, you have a crude (and large, and hard to work with) version control system already. You probably have to say things like “no, it’s the one with the time stamp in March, remember, because in April that was the one that says ‘final’ but it’s not really …”. Maybe you’re afraid to throw any of the files away because you’re not 100% sure you remember exactly why you made that particular version, but you’re a little chagrined that you have 10 versions of (mostly) the same .csv. If your files are large, you might have a storage problem as well!
And what about your research collaborators? Are you sending these files back and forth over email for each member to make changes? What if someone accidentally works on a version that doesn’t include the changes of another collaborator? Working by committee is hard when you rely on local copies. Maybe you have just one copy on a server that everyone has access to, which is better. But while you have the file open, your RA or co-PI can’t make changes. Frustrating!
Good news! There is a better way to do version control. While there are several methods out there (e.g. Subversion), “git” has won the market.
git 101
Let’s start with some vocab.
Git? git? GitHub???
“git” is a command line tool, a program that uses a set of rules that governs how the git version control system works. You can use it by itself and do everything you need to, if you’re comfortable working on the command line. Lots of people do just that!
“GitHub” is a website (and ancillary software like GitHub Desktop that can work with the website or independently from it) that uses “git” and makes it a bit easier to use. There are other big players in the market that use git (repository software like Sourcetree, or software add-ons in popular software like R), but GitHub is the most popular platform that people tend to use with the git protocol. If you’re new to coding, working on the command line, or just prefer a more visual interface, GitHub can be very helpful.
Why GitHub?
While git by itself is great at version control and keeping track of your changes, GitHub wraps all of the sometimes complex inner workings of git into a visually pleasing, easy to understand user interface. Instead of having to learn a bunch of command line tools, GitHub (both the website as well as the client software you can run on your computer) allows you to see things like version history, file change summaries, etc., very simply. It’s fairly intuitive for most day-to-day uses.
GitHub (the website) is a also place for your files to live with version control applied to them, so you can think of it as a souped-up remote server. That means it’s great not only for version control (which you could just do on your local computer using a git-enabled product like GitHub Desktop), but also having a central hub for all your files that you and your collaborators can use as the canonical source of the best, most up-to-date files.
There is a public GitHub website that you can use to host your files for free, if you don’t mind them being public and visible for all to see (https://www.github.com. CHOP also has a local GitHub server that looks and acts almost 100% the same as the public GitHub site, but it’s local to CHOP, so you don’t have to worry about violating intellectual property rules (or, if you make your data sufficiently private, even HIPAA worries). That can be found at https://github.research.chop.edu.
Navigating GitHub
The nice thing about git is that when you use it, your computer only has one copy of every file that’s being versioned. So instead of having multiple similar file names that all refer to (mostly) the same data, you just have one, with a history of changes. Instead of hanging on to every single complete version of a file, git works by remembering the differences from one version to the next, so it can “play back” the changes to give you any version you want. No more appending “final_final_no_really” to indicate why file A is different than file B.
For example, check out a CHOP GitHub page that has some simulated data. Note that all of the data is completely fabricated, so it’s okay to make it publicly viewable by everyone at CHOP who is using CHOP’s github. Here’s the link: https://github.research.chop.edu/paytonk/simulated_data_example. You don’t have to be logged in to CHOP’s GitHub to look at this, by the way, but you do have to be on the CHOP network. It shows just one file, and you can look at all sorts of different versions of it, but it’s only one file. And it’s that way on my local computer, too, thanks to git!
As an aside, I should point out that using git for versioning data is somewhat controversial, as git was built and intended for versioning code, for which each line is a kind of logical unit.
Some kinds of data, like key value pairs with lots of line breaks (say, in JSON), work really well with git. Other data types like .csvs (which store a lot of logical units of data in a single line), might feel a little clunky without customizing your use of git. My take on this is that versioning your data with git is better than the alternative of not using version control at all.
I put in various manipulations of data that mimic what might really happen in the lifespan of a dataset and saved various versions along the way (using git’s “commit” function). Let’s take a look at what this project (we use the term “repo” or “repository”) has in it. Let’s take a look at a few elements.
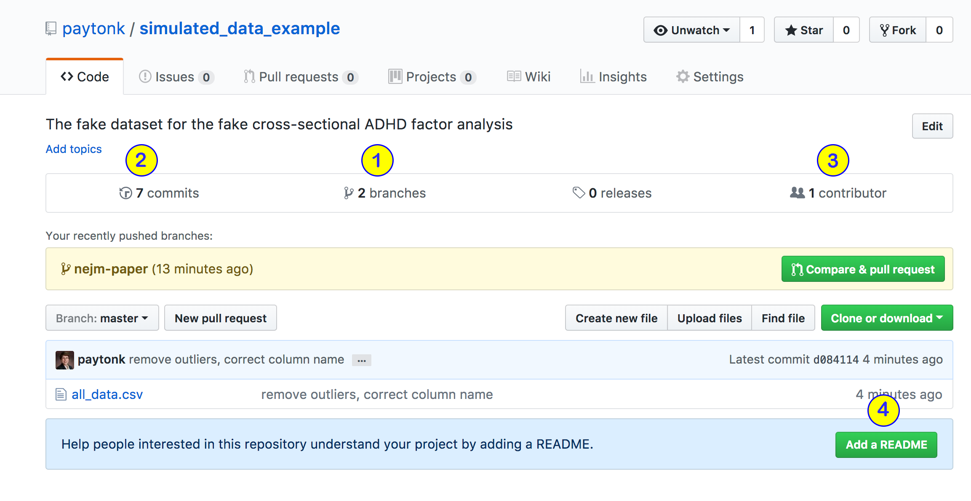
(1) Branches
Branches are used when you want to simultaneously hang on to several “correct” or “most recent” versions, not just your main (or “master”) version. In our case, we need to separately keep track of the datasets that are associated with various publications, so I started a “NEJM paper” branch just to keep track of what we sent to the New England Journal of Medicine. Click on the “2 branches” text to see them.
(2) Commits
A “commit” happens when someone (a programmer, a data analyst, a researcher) decides that they’ve changed the file enough that they want to save a version of it for posterity. When you commit a file, you are asked to give a comment describing what you did. Sometimes, in larger groups (like programmers working on a big software project), there will be some agreed-upon way to write these, but really you can put whatever you want. A commit could be a change or two to one file, or multiple changes across several files.
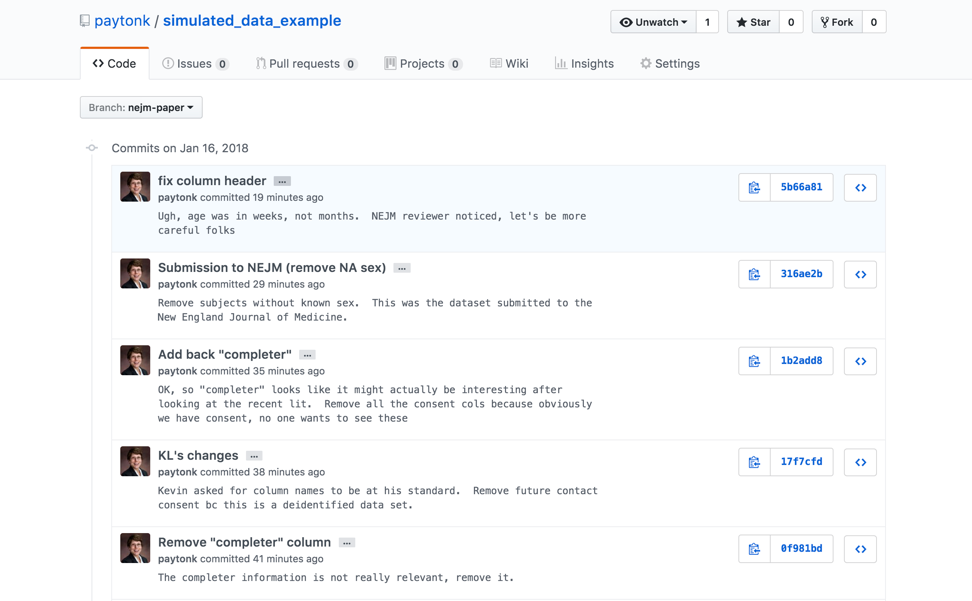
The number of commits shown in this dashboard means the number of commits in the “default” branch (usually called “master”). You can click on the “7 commits” text, however, and see a drop-down menu that will allow you to see the commits for any branch of the repo. Beside the commit “comment” (just a few words) there might be three dots that represent the “details” optionally added by the committer. See below, where I expanded all these details!
(3) Contributors
Even if you make your GitHub repository public, that only makes it public for reading, not for making changes. You have to expressly give permission for people to become contributors (people who can commit file changes). Or, someone who’s not a contributor, but has access to your repository, can make some changes and request that you apply them (called a pull request or PR).
(4) README
README.md is a “markdown” (thus, .md) file that is optional but is nice to have. It explains what the repository contains, how to use it, etc. For example, check out a README that I did on a repo I worked on in my spare time: https://github.com/pm0kjp/neurodiverse-blog-data-miner.
In our next GitHub educational document, I’ll get you started with your own repo. In the meantime, look around at the various public repos available on GitHub.com (https://github.com/explore) or CHOP’s enterprise version of GitHub (https://github.research.chop.edu/repositories. Can you figure out how to look at older versions in their entirety? How to look at just the lines changed from one version to the next?