
Arcus Data Repository: A Fast Track to Research
CHOP already has Epic and a large, data-rich data warehouse (the CDW). Why does Arcus have an additional data repository with clinical data? In this article, let’s take a look at how the Arcus Data Repository (ADR) positions researchers favorably and may accelerate your research.
De-identified Data
An initial strength of the ADR is in the privacy scope of its data. Researchers who use the ADR within an Arcus project can get access to de-identified clinical data. Research conducted on de-identified data from the ADR is not considered human subjects research. This means that IRB oversight is not required, reducing administrative burden and speeding time to science. Retrospective studies of de-identified data can be carried out rapidly, which is a boon to researchers with limited time, lab resources, and funding.
Need identified data? That’s available, too, with oversight from the Institutional Review Board. We have organized datasets that are scoped to include various levels of privacy and sensitivity, and have worked closely with the IRB to streamline how researchers can work with our data.
Normalization: A Bit of Background
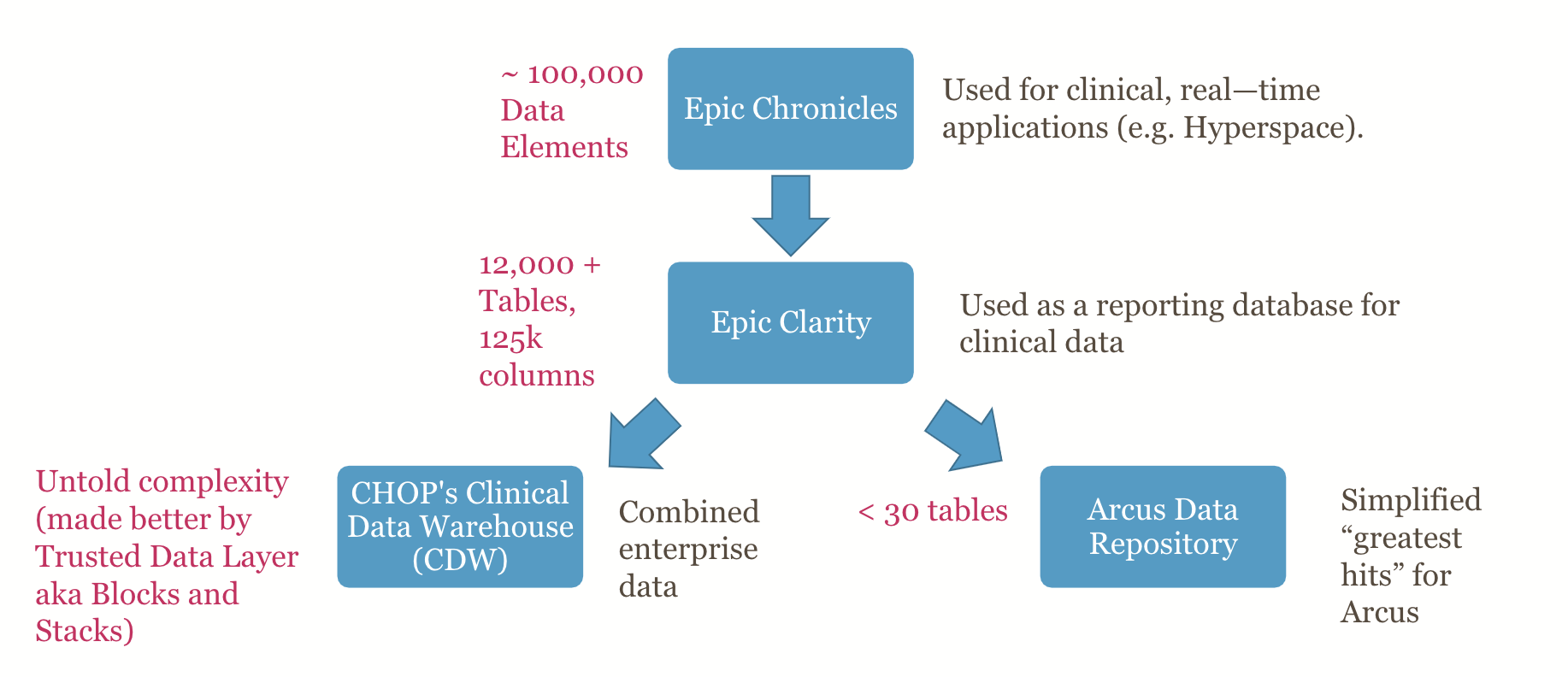
Working with clinical data is notoriously messy. Like most databases, Clarity (the reporting database for Epic) and the CDW (CHOP’s Data Warehouse), which both hold not just Epic data but data from related and legacy systems are highly “normalized” – a technical way of describing how data is split up into various tables to avoid needless repetition of the same information over and over. Information repeats because of one-to-many (1:many) relationships. For example, a single patient can have multiple encounters, a single encounter has multiple medication orders, and so on. Normalization is required to keep from having to repeat the same information (patient information or encounter details) hundreds or thousands of times. That’s good, but given the complexity of clinical data, normalization means that there are thousand of tables in most clinical databases. These tables can share various keys that can be used to re-link the data together across table joins.
Consider a (very simplistic and unrealistic) normalized (split up across tables) dataset:
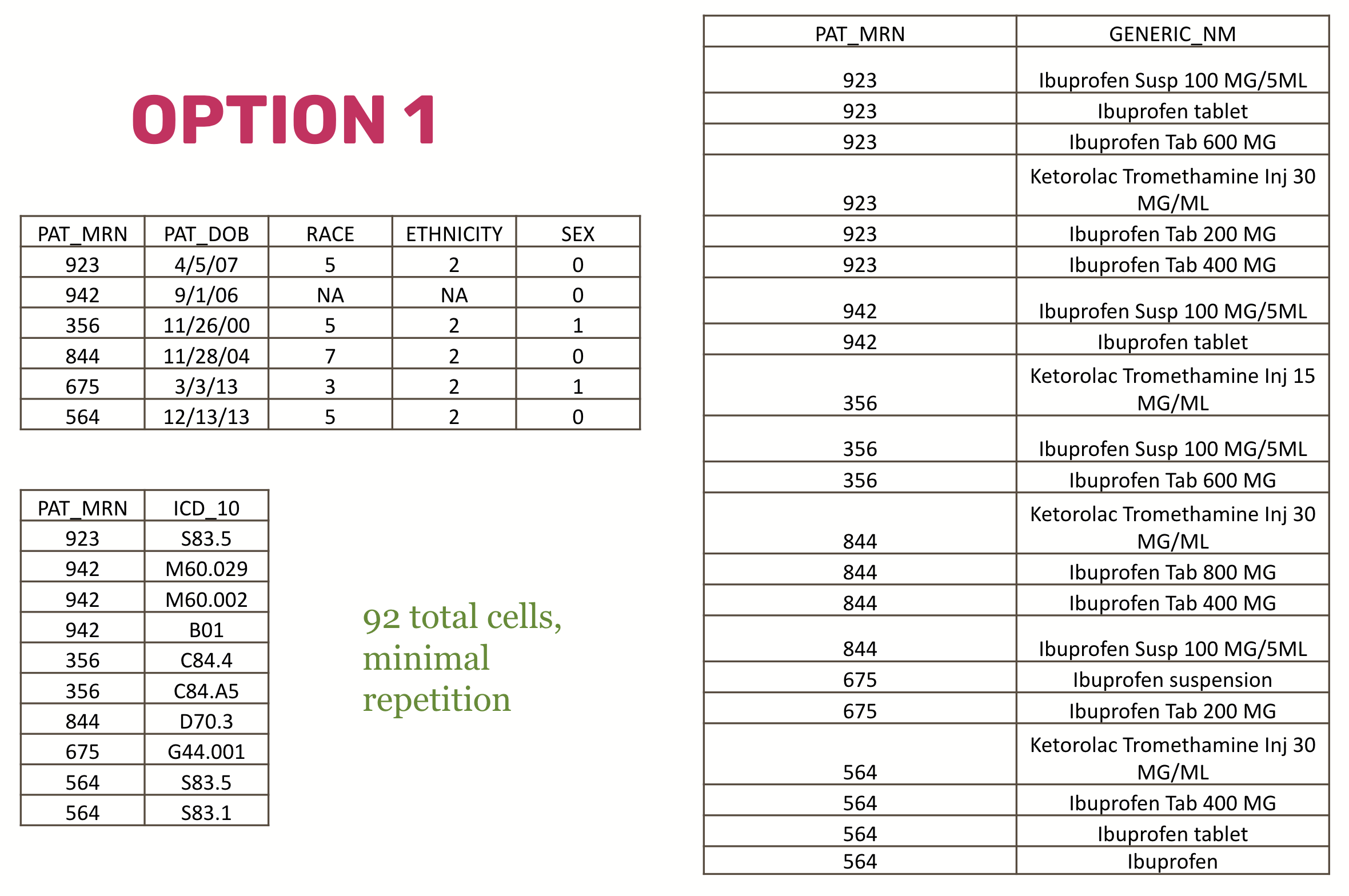
And compare that with a non-normalized dataset that has a single table and lots of repetition:

Normalization is important for large databases that need to accommodate large amounts of data that may stream in at high velocity. Very strict normalization, however, makes data hard for humans to understand and assemble. For example, to get from a specific patient to a medication name, you might have to associate an MRN to all associated encounters, take those encounter ids and look up all the associated medication orders, trace the order id to the medication codes included in that order, and all the medication codes to a medication name in a lookup table. And keep in mind there may be dozens of medication-related tables that you might have to look at to figure out which one is the right one for you.
Simplified Schema
Currently, there are several groups across CHOP that have years of experience of knowing the complex interrelationship of clinical data tables in sources like the CHOP Data Warehouse and Epic’s Clarity database. These data analysts know how to navigate potentially conflicting or erroneous information and how to write complex, hundred-line-long SQL statements to extract just the data a researcher (or a clinician) needs.
But for more simple data requests, Arcus offers a more simplified, easy to navigate Arcus Data Repository. The ADR still uses several keys (ids that are common across tables, like encounter_id) that link related data, and you’ll need to learn SQL to use the Arcus Data Repository effectively, but some denormalization has been done to make tables easier to understand in context. There are fewer tables to look through, and fewer table joins required to get the data you need.
Accessing Data
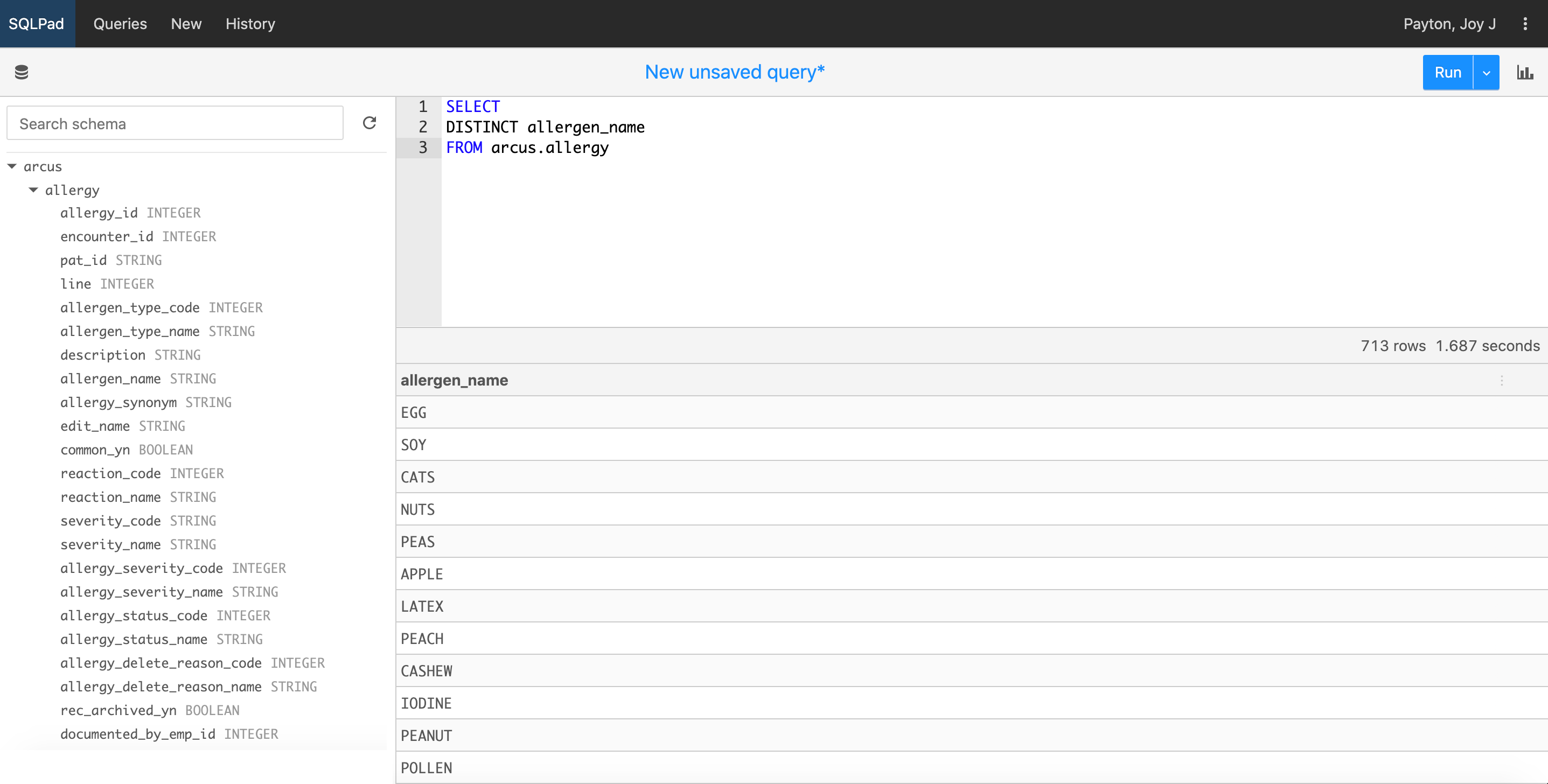
A simpler schema means Arcus can put data at your fingertips using a SQL client that will allow you to select the data you want from a reasonable number of tables. There are two primary ways to interact with the Arcus Data Repository. For most users, the data you need for your project (some subset of the ADR and, perhaps, additional data you need) will be available for you to work with in a computational lab provided by Arcus. After using SQL to extract, clean, and combine data, you can use R or Python to analyze, visualize, and describe data and share your methods. See below for one example of how a very simple SQL query involving a single table might look:
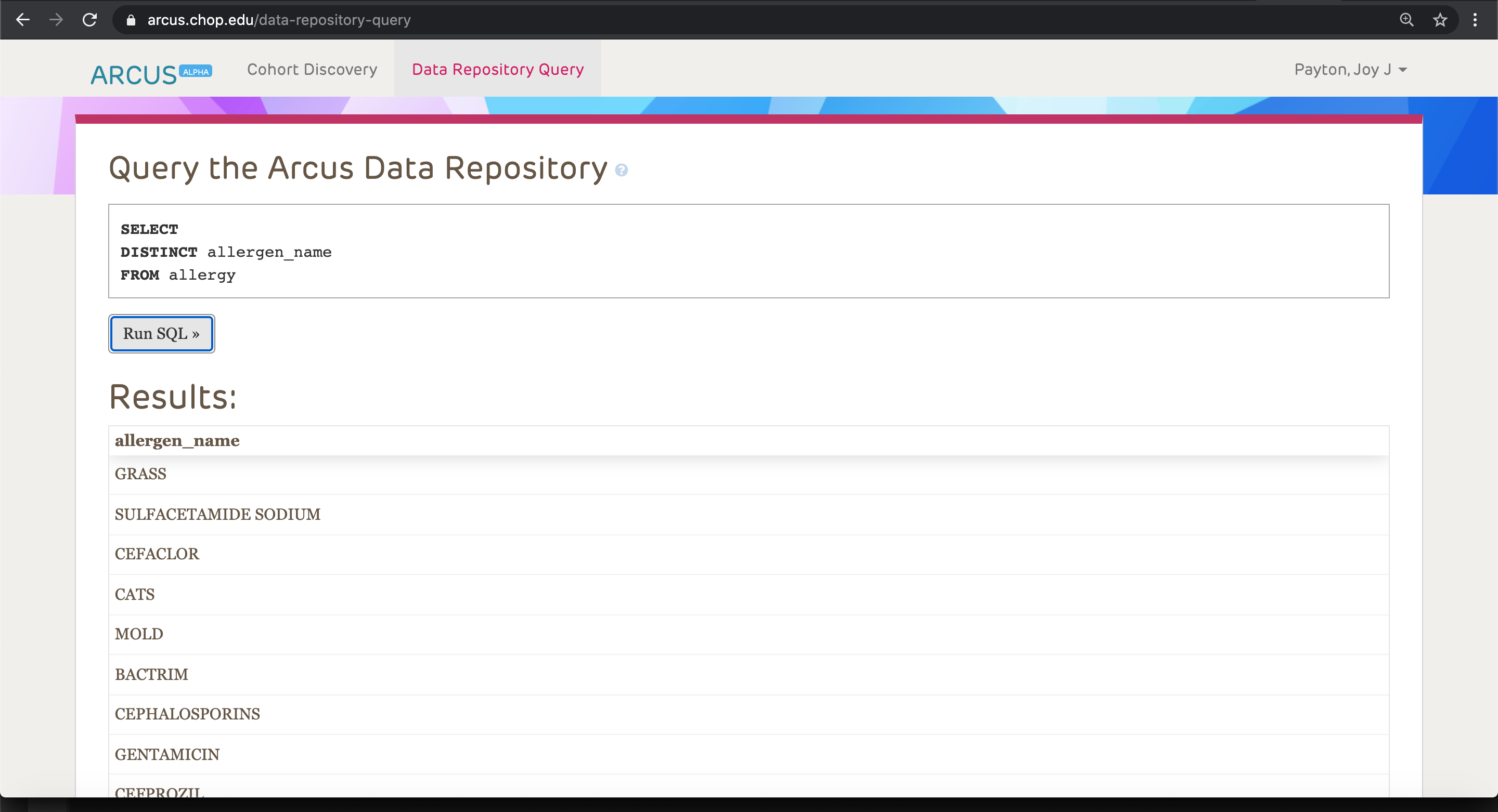
For others, who have more experience and are interested in exploring data in a self-service way, we have a SQL endpoint you can use once you’re logged into the Arcus application. Because this data is self-service, we do throttle the results, so that you will only be able to view a maximum of 1000 rows. That means you can do a bit of investigation and looking around, but you won’t be able to view a full patient-level dataset. However, if you want to do counts (for example, how many patients have allergy flags related to a certain allergen), you’ll get a correct count executed over the entire CHOP patient database, which can be helpful for grant applications and feasibility analysis. This is what a simple search in the self-service Arcus application might look like:
The Goldilocks Principle
We aim to make the ADR “just big enough” – with enough fields to be useful for most researchers, but without the thousands of details that are only interesting for very specific use cases. Arcus data experts can add data to an Arcus project beyond what’s in the Arcus Data Repository, if you have specific data in mind we haven’t included in the ADR, but often, the ADR alone is sufficient.
Accuracy and Speed
The ADR has been thoroughly tested and vetted, and provides data provenance information on every field, so that you can understand what system the data comes from. It incorporates standard enterprise and research definitions, taking the guesswork out of figuring out things like whether a medication was given to the patient or simply dispensed for bedside availability but never administered. Besides the data repository itself, there is also an easy to use metadata browser that describes in detail what’s contained in each table and what every field name means.
Additionally, the ADR is cloud-supported, on BigQuery, a high-speed, easy to use SQL service offered by Google Cloud Platform. You will get results quickly and easily in a system that is designed to provide quick throughput for multiple users.
Not a Replacement
The Arcus Data Repository isn’t intended to replace the CDW, Clarity, or Epic. It’s intentionally a very simplified set of data that exists to offer many researchers important, faster access to data that can be used with more basic SQL skills. The ADR supplements existing tools and allows researchers faster, no-cost (or lower cost, depending on how much advanced pre-cleaning you want) access to data. Interested in finding out more? Email arcus-support@email.chop.edu to ask questions or start a conversation around getting your own Arcus lab with ADR data for your project!